
Humanoid robots, the 1000 TWh problem, and a recipe for blackouts
Currents: AI & Energy Insights - February 2025

Welcome back to Currents, a monthly column from Reimagine Energy dedicated to the latest news at the intersection of AI & Energy. Every last week of the month, I send out an expert-curated summary of the most relevant updates from the sector. The focus is on major industry news, published scientific articles, a recap of the month’s posts from Reimagine Energy, and a dedicated job board.
1. Industry news
A new smartest AI on Earth, every month
With the DeepSeek craze cooling down, February was a busy month for all major companies working on AI products. I like the following chart because, besides highlighting each model’s capabilities, it also reflects how quickly different organizations can innovate. According to this chart, xAI seems to have the steepest improvement curve, if the self-reported results of the reasoning version were to hold true.

Let’s have a look at all the major announcements:
OpenAI released GPT 4.5, temporarily available only to Pro users, while they work on adding more GPUs. I haven’t had the chance to test it yet, but the general sentiment seems to be that the model’s capabilities are underwhelming compared to the massive increase in costs (15-30x higher than GPT-4o). The o-series will probably still be better for most STEM tasks, but 4.5 could apparently thrive in research or creative applications, although it feels hard to justify the price tag. Another interesting update is that as of February 25, Deep Research is available to all users on all paid plans of ChatGPT. I haven’t tested it yet, but I hope to find some time to compare it with Gemini’s, Grok, and Perplexity, and potentially write an article about it.
Anthropic finally released Claude Sonnet 3.7, together with Claude Code, a command-line agentic coding tool. Sonnet 3.7 is the first “hybrid” reasoning model, in which it will avoid reasoning for very simple queries. When integrating with the API, there’s also the option to have granular control over how much (or how little, or not at all) the AI should think before responding. This is one of the features that I’m most excited about testing, as it allows embedding a reasoning model in an application without making users wait forever for a response.
xAI released Grok 3, trained on a massive cluster of 200,000 Nvidia H100 GPUs. Elon Musk called it the “smartest AI on Earth”. The claim is mainly based on self-reported results, so we’ll have to wait for independent evaluations to confirm that. Grok 3 will also have its own DeepSearch mode: the first Grok agent able to search the internet and distill information.

The Colossus supercomputer cluster by xAI Perplexity announced their own Deep Research tool and that they’re working on an “agentic” browser called Comet.
Google released Co-scientist, a multi-agent AI system designed to support researchers in various aspects of the research process. It is currently only available to selected research organizations.
Figure, a humanoid robot startup, announced it would break out of their partnership with OpenAI after achieving a breakthrough on their side. They also claimed that they will show “in the next 30 days something no one has ever seen on a humanoid”. In another X post, they unveiled grocery-sorting robots, and announced plans to ship 100k robots within the next four years. I’m excited to never have to do laundry again, but I also have to admit that their videos remind me of one of those movies where it doesn’t end well for humans…

What I’m thinking
Increased competition is bringing us increasingly powerful tools every month. I’ve been working to implement LLM intelligence within Ento for the last few months. I love that as I work to make our application interface better, the models are also improving in parallel. We’re at a level of modularity that makes it incredibly easy for us to switch between different models as smarter, cheaper, and faster versions appear.
At the same time, I feel like we’re lacking an easy and structured way to benchmark different models on our concrete data and tasks. There are plenty of general benchmarks out there, but how does Gemini or o3 fare compared to Sonnet 3.7 for my concrete task? Right now I have to come up with creative and time-consuming ways to compare the outputs, while I would love to have a tool to perform structured comparisons in my own application. If you know of one, let me know!
The 1000 TWh problem
With higher AI capabilities, increasingly powerful models being deployed, and more companies joining the frontier model race, many are concerned about the climate impact of AI. The following figures on projected data center consumption for the US and China can help us get a better understanding of the situation. We’re talking about a potential combined consumption of almost 1000 TWh by 2030, with data centers potentially consuming up to 12% of total US electricity by 2028.
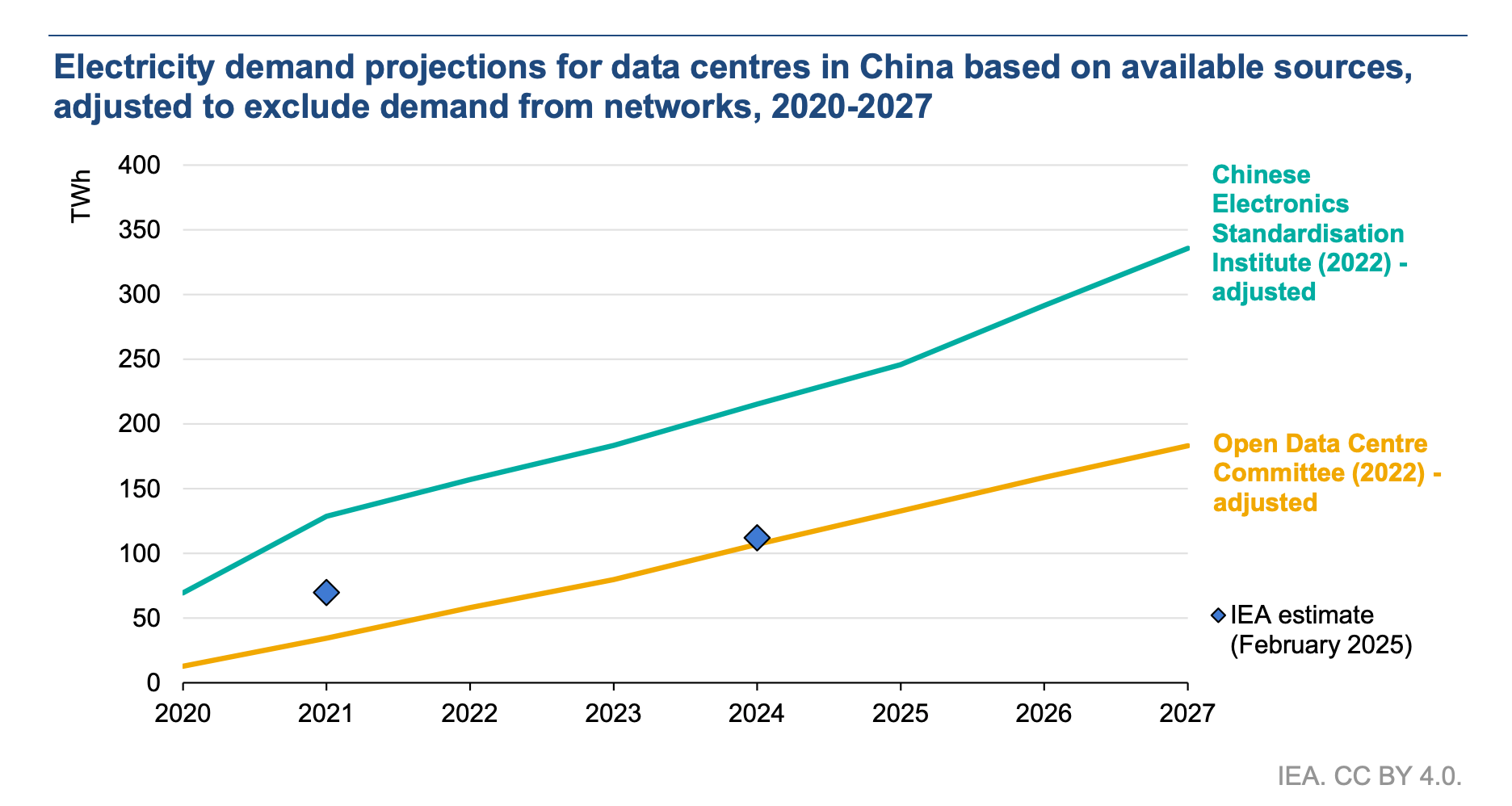
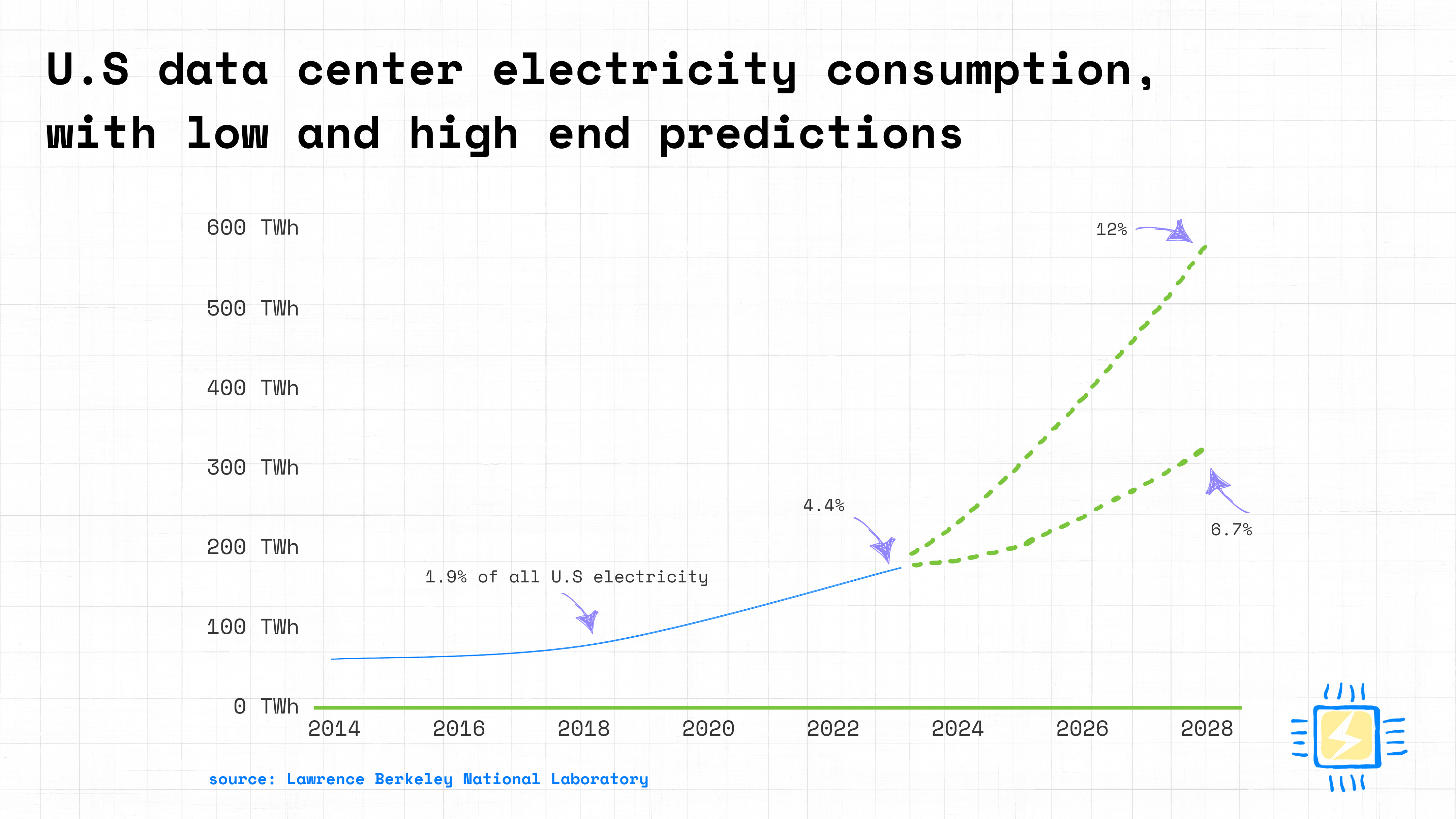
Given these staggering numbers, there’s increased interest in assessing and improving the computational efficiency of LLMs. Hugging Face, in collaboration with Salesforce, announced the AI Energy Score project, a public benchmark aimed at standardizing the measurement of inference compute requirements for different models.
Google also released a detailed report on the carbon emissions of their AI hardware. It’s interesting to see that operational emissions are still responsible for 75-90% of total emissions, even when accounting for the data centers’ construction phase and hardware manufacturing.
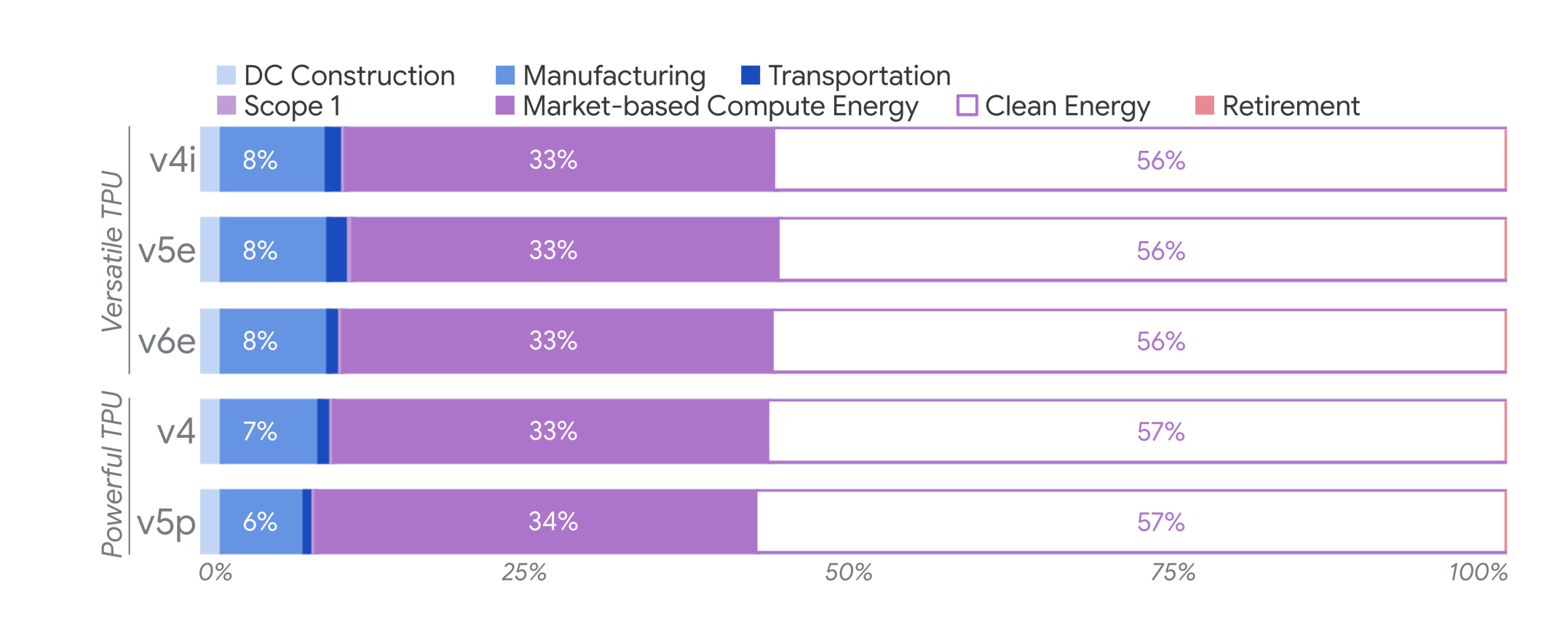
Google is still pursuing its ambitious goal to run all of its Cloud on 100% CFE, which is impressive given the developments of the past 2 years. It means that they have a lot of confidence in their ability to improve both hardware and software efficiency while also deploying renewables and getting into favorable PPAs.
What I’m thinking
Data center consumption is definitely something that should be taken seriously. At the same time, I believe we have tremendous room for technological improvement. In the figure below, we can see how the biggest drivers of US electricity consumption are actually buildings and data centers.
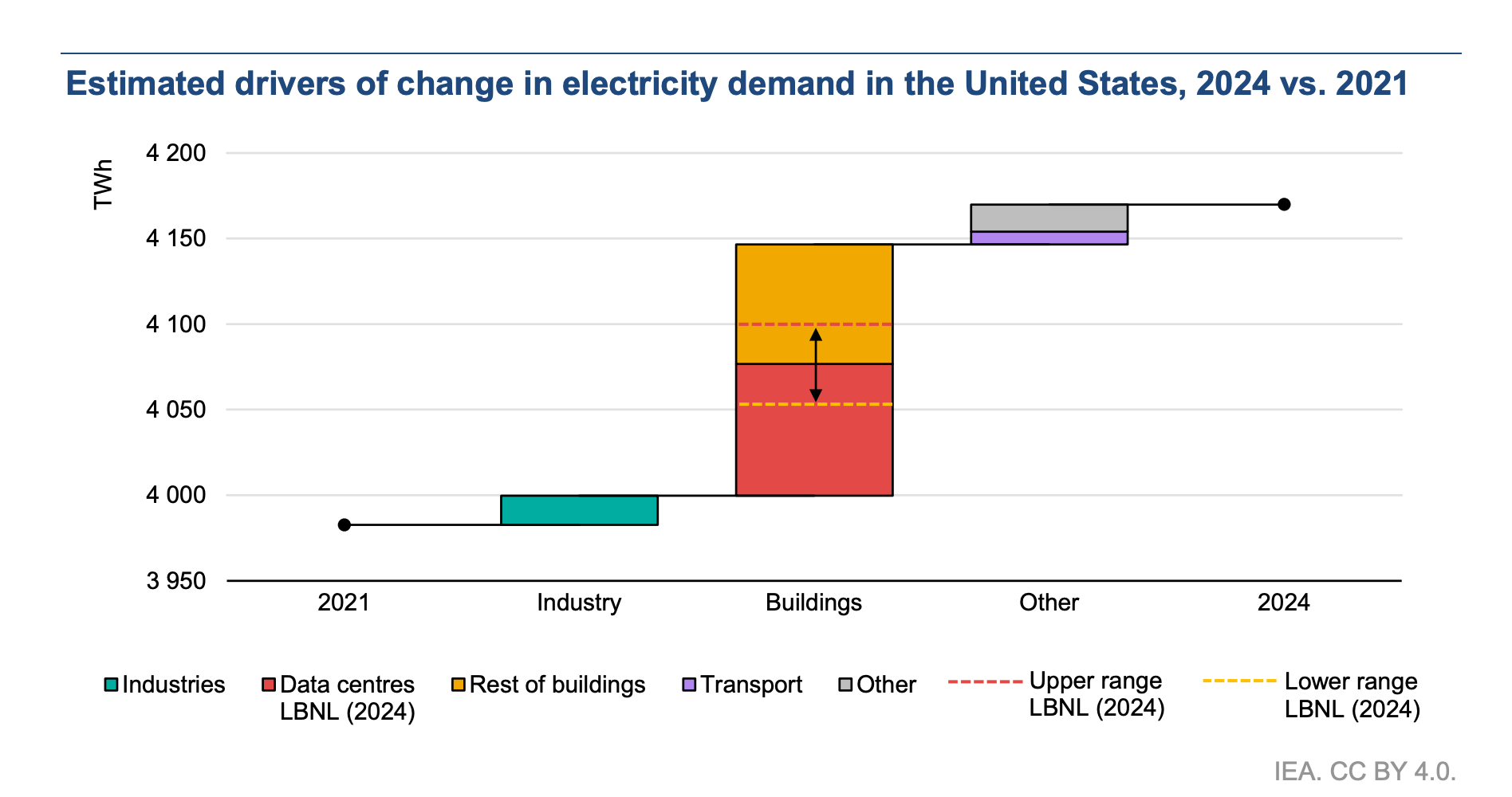
For both of them, we can significantly reduce emissions simply by deploying more renewables coupled with (AI-powered) demand-side flexibility solutions. While doing research for this article, I just came across these two publications about “carbon-aware machine learning inference” for image recognition and LLMs. You should give them a read as they’re super interesting.
The AI Energy Score project is also a step in the right direction. Standardizing efficiency benchmarks is very necessary. At the same time, I feel like the quality of the output should be taken into account as well. It’s great to see a ranking of which model is more efficient at inference in terms of GPU compute, but when evaluating which LLM I’m going to embed in my application, I need to be able to see the efficiency together with a measure of the output quality. Much of the model efficiency discussion focuses on the number of tokens processed per unit of energy consumed, but I find this misleading. o1 and GPT-3 could receive the same amount of tokens and output the same number tokens, yet their result can be incredibly different. For me, the ultimate benchmark should be amount of output intelligence (which will vary depending on the type of task) per Wh consumed. We’ll then need to look at the Pareto frontier for the quality vs. cost trade-off.
Lights out in Chile
Many of you will have heard about the blackout that plunged Chile into darkness on February 25th. The lives of many people were disrupted, and there have been at least three confirmed deaths among people relying on electricity to live. But what I want to focus on here is how this situation represents a scenario that will become increasingly common globally, as we keep installing more renewables where the generation potential is highest, while not investing enough in transmission grids. Here are a few interesting facts to consider:
Chile is leading South America’s renewable energy expansion, with solar PV and wind now comprising around 40% of the country’s installed capacity.
Chile's installed capacity is set to increase by 139% by 2060, driven predominantly by solar, battery storage, and onshore wind.
By 2060, over 90% of Chile’s power generation will come from renewables, with solar accounting for nearly half of the total installed capacity.1
The transmission system infrastructure of Chile is quite limited, with the north (where most PV power plants are) and the center (where most of the demand is) of the country being connected by a single main 500 kV line.
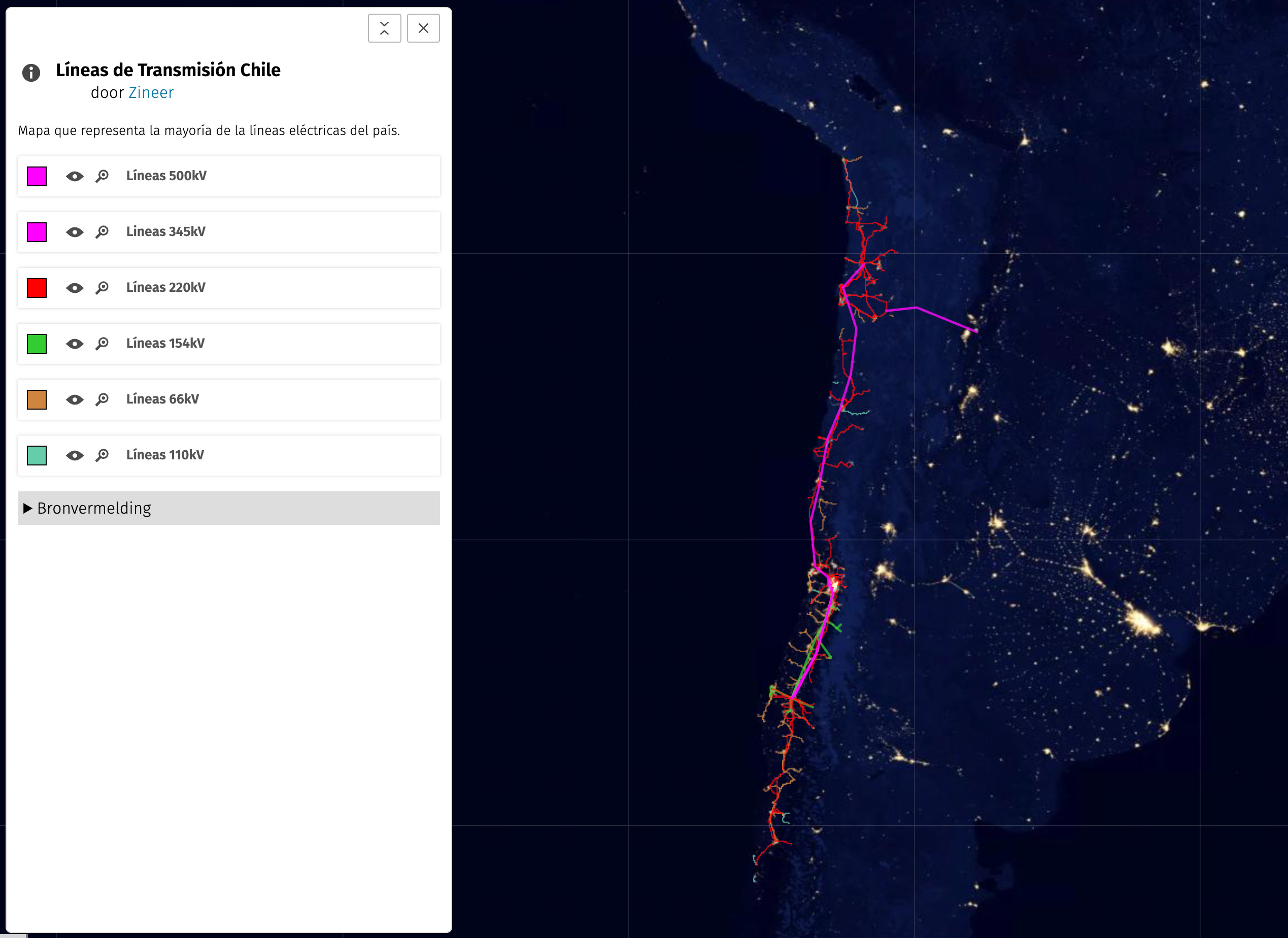
Most solar power production plants are currently concentrated in the north of the country.
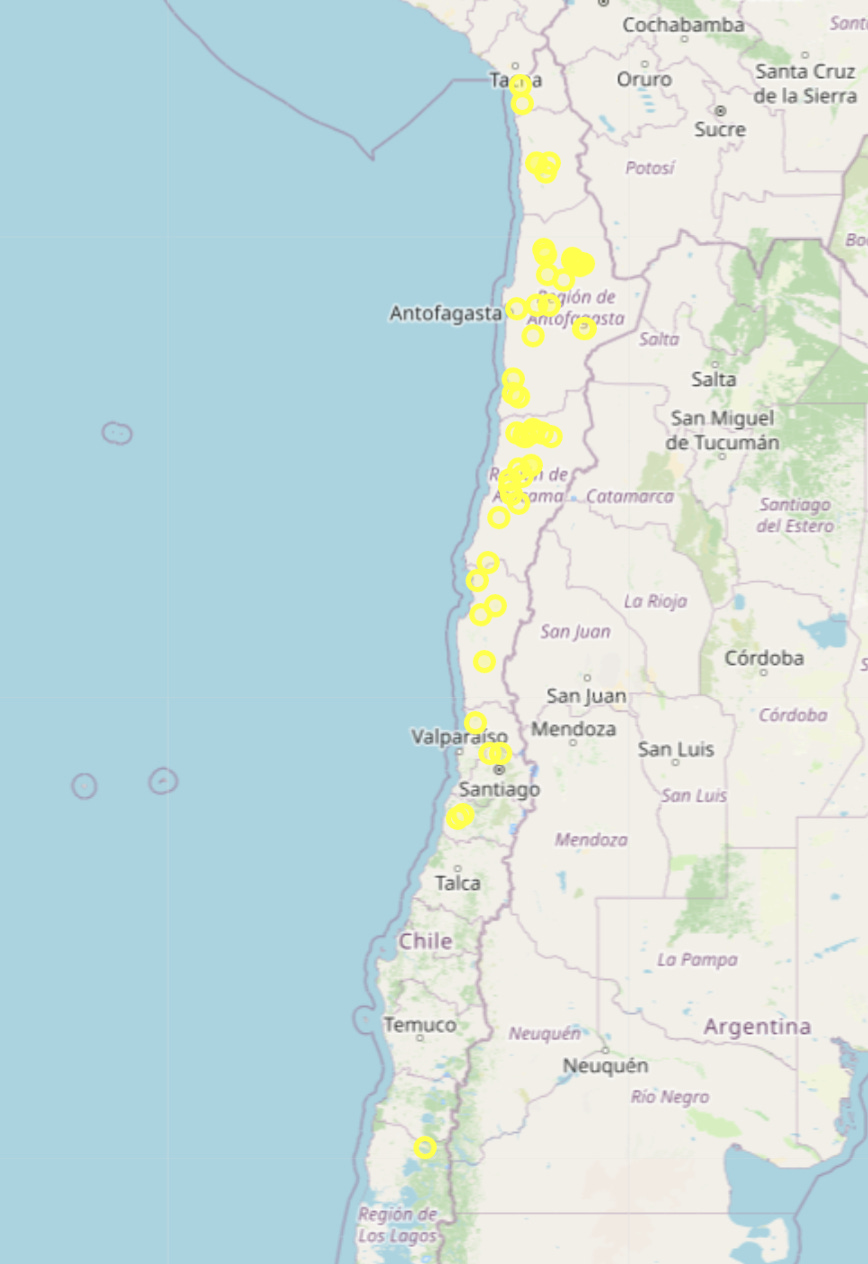
Given the photovoltaic power potential of the territory, this is a trend that is likely to continue over the coming years:
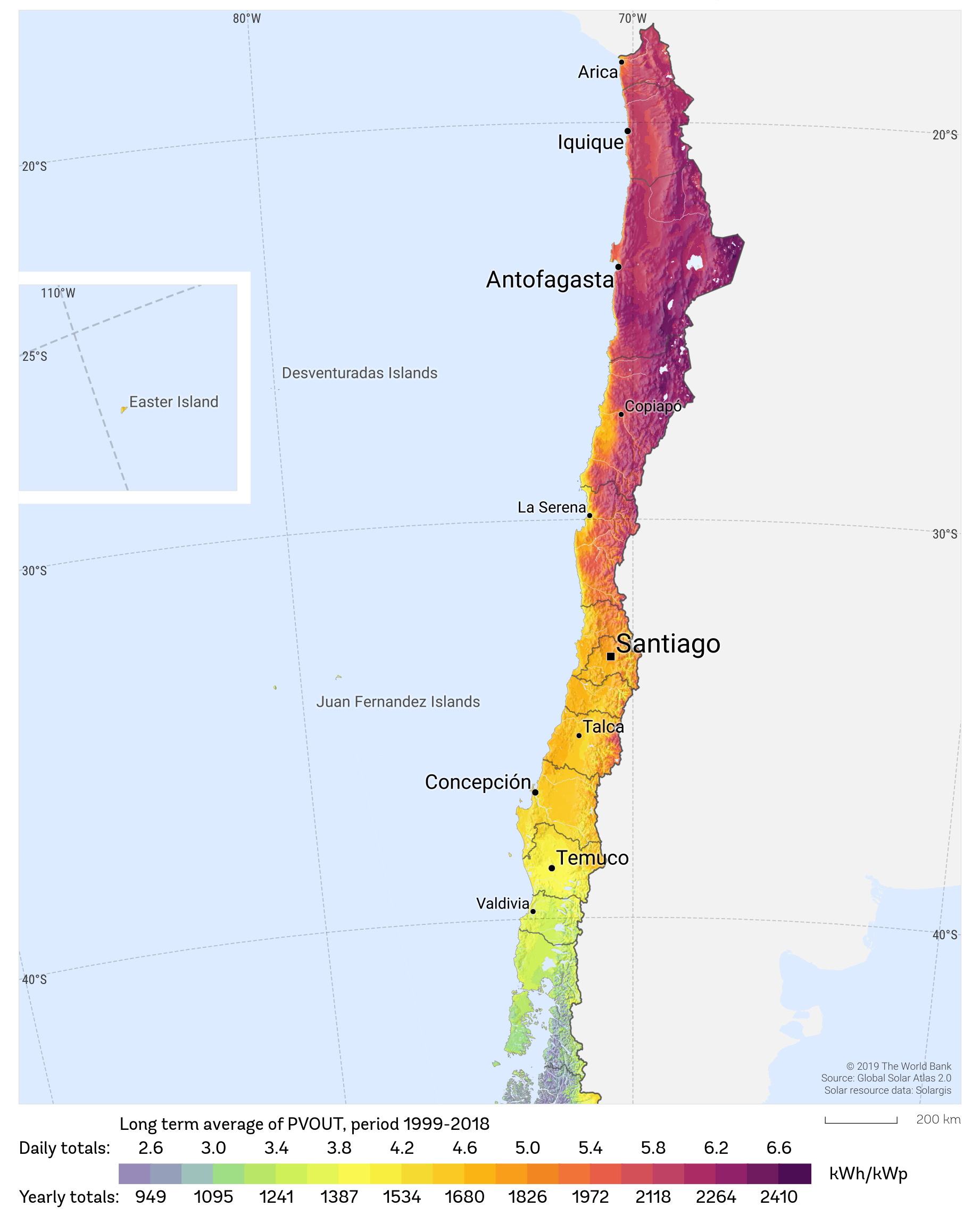
Chile’s geography exacerbates the situation, but having high renewable capacity far away from main demand centres with limited transmission infrastructure is a recipe for blackouts. The solution? As usual: invest more in grids, deploy energy storage, and facilitate demand-side flexibility mechanisms.
What I’m thinking
Aside from the technical energy aspects, researching about this blackout got me thinking about how our society has grown extremely dependent on electricity. Many people were stuck in elevators for hours; it took two hours to evacuate the Santiago metro, which transports 2.3m passengers per day; and patients’ care in hospitals was disrupted. This is a reminder that, as much as we care about lowering emissions, ensuring energy security must be the first priority of any energy policy.
Chile is a very fascinating country under many aspects. If you’re interested in learning more, I recommend you read this article from one of my favorite Substack authors. I really enjoyed it because it’s filled with maps, and I love a good map!
2. Scientific publications
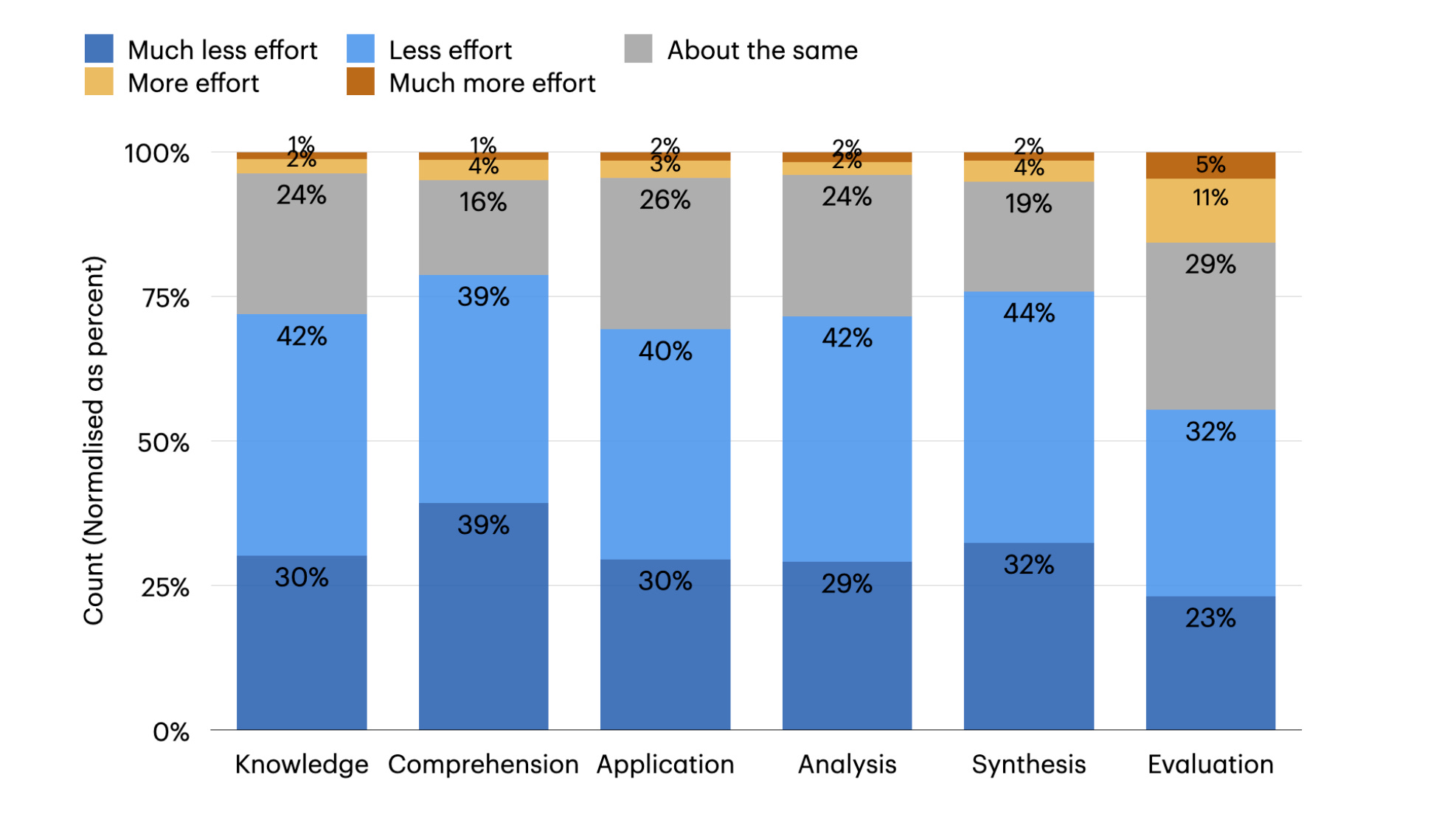
The Impact of Generative AI on Critical Thinking: Self-Reported Reductions in Cognitive Effort and Confidence Effects From a Survey of Knowledge Workers reveals that while AI tools can reduce the perceived effort of critical thinking tasks, they can also lead to over-reliance on AI, diminishing independent problem-solving abilities. The study also shows that higher confidence in AI correlates with less engagement in critical thinking. Another study, Generative AI can harm learning, conducted in a high school math setting, demonstrates that while AI-based tutors can boost immediate performance, removing AI access can lead to worse learning outcomes than if AI was never introduced, suggesting a "crutch" effect.
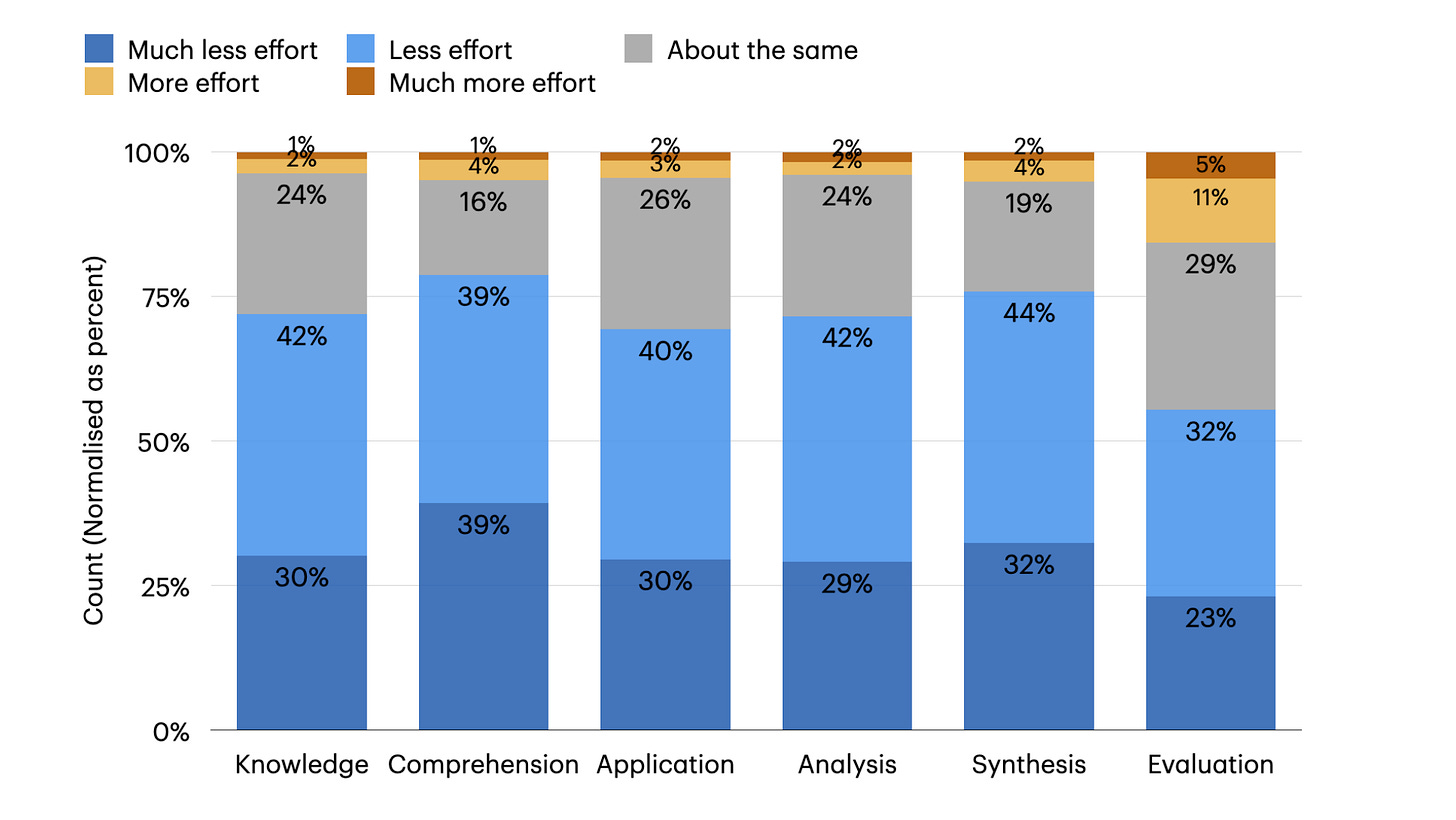
Distribution of perceived effort (%) in cognitive activities when using a GenAI tool compared to not using one. Source: The Impact of Generative AI on Critical Thinking What I’m thinking
While I’m an enthusiastic early adopter of many of these technologies, I also think that one of the biggest risks is using them to replace critical thinking altogether. The negative effects of this are clearly visible in our social media feeds, which are getting flooded by bland content that sounds the same. I now typically stop reading as soon at the first “delve”, “pivotal”, or “transformative”.
Personally, I avoid using AI to write as much as possible. At the same time, AI is boosting my productivity significantly on the coding side. This article aligns well with my thinking about AI-assisted coding, which you can also find in this post.
It’s evident that more work must be done on designing AI tools that actively promote critical thinking. We need an approach that leverages AI's strengths without compromising fundamental cognitive skills. Mira Murati, the former OpenAI CTO, agrees. Her new startup, Thinking Machines Lab, is reportedly focusing on improving the interaction between humans and AI.
SolNet: Open-source deep learning models for photovoltaic power forecasting across the globe introduces an open-source deep learning model generator for PV power forecasting. The architecture uses transfer learning by first pre-training on PVGIS data and then fine-tuning on observational data. The results show RMSE improvements of 10-15% in data-scarce environments.
What I’m thinking
In the last Currents issue, we discussed the potential of using transfer learning when training models for automated building control. This month, I was happy to review yet another application where transfer learning is showing great promise. I also really like that this publication is accompanied by reproducible open source code (accessible here). In my opinion, when a scientific paper includes reproducible code, its impact is so much higher.
3. Reimagine Energy publications
In my latest code tutorial I look at how a single energy conservation measure can lead to a 28% reduction of rooftop solar ROI:

4. AI in Energy job board
This space is dedicated to job posts in the sector that caught my attention during the last month. I have no affiliation with any of them, I’m just looking to help readers connect with relevant jobs in the market.
Internship: Imbalance & Imbalance Price Prediction in the Belgian Electricity Market at ML6
Data Scientist - AI Benchmark Architect at PassiveLogic
Lead Data Engineer at Octopus Energy UK
Energy/Environmental Technology Researcher at Berkeley Lab
Conclusion
With so much going on in the sector, it’s not easy to follow everything. If you’re aware of anything that seems relevant and should be included in Currents (job posts, scientific articles, relevant industry events, etc.), please reply to this email or reach out on LinkedIn and I’ll be happy to consider them for inclusion!
Chilean Power Market Forecast by Aurora Energy Research
You are sencillamente impresionante 🤩
Also — Chile tangent for anyone looking to learn more about how the grid has developed: https://epic.uchicago.edu/insights/the-dynamic-impact-of-market-integration-evidence-from-renewable-energy-expansion-in-chile/